
विषय
- द स्केप्टिक्स क्लब
- संवैधानिक तंत्रिका नेटवर्क (CNNs)
- नो बग्स, नो स्ट्रेस - योर स्टेप बाय स्टेप गाइड बाय स्टेप गाइड टू लाइफ-चेंजिंग सॉफ्टवेर विदाउट योर लाइफ
- लॉन्ग शॉर्ट-टर्म मेमोरी (LSTM) इकाइयाँ
- जनरेशनल एडवरसियरी नेटवर्क (GAN)
- निष्कर्ष

स्रोत: Vs1489 / ड्रीमस्टाइम डॉट कॉम
ले जाओ:
क्या "डीप लर्निंग" उन्नत तंत्रिका नेटवर्क का सिर्फ एक और नाम है, या क्या इससे कहीं अधिक है? हम गहन सीखने के साथ-साथ तंत्रिका नेटवर्क में हाल की प्रगति पर एक नज़र डालें।
द स्केप्टिक्स क्लब
यदि आप, मेरी तरह, स्केप्टिक्स क्लब से संबंधित हैं, तो आप भी सोच रहे होंगे कि गहरी सीख के बारे में सभी उपद्रव क्या हैं। तंत्रिका नेटवर्क (एनएन) एक नई अवधारणा नहीं हैं। मल्टीलेयर परसेप्ट्रॉन को 1961 में पेश किया गया था, जो कि केवल कल ही नहीं है।
लेकिन वर्तमान तंत्रिका नेटवर्क केवल एक बहुपरत अवधारणात्मक से अधिक जटिल हैं; उनमें कई और छिपी हुई परतें और यहां तक कि आवर्तक कनेक्शन भी हो सकते हैं। लेकिन पकड़ो, वे अभी भी प्रशिक्षण के लिए backpropagation एल्गोरिथ्म का उपयोग नहीं करते हैं?
हाँ! अब, मशीन कम्प्यूटेशनल शक्ति able० के दशक में या s० के दशक में भी उपलब्ध थी। इसका मतलब है कि अधिक जटिल तंत्रिका आर्किटेक्चर को उचित समय में प्रशिक्षित किया जा सकता है।
इसलिए, यदि अवधारणा नई नहीं है, तो क्या इसका मतलब यह हो सकता है कि गहन सीखना स्टेरॉयड पर तंत्रिका नेटवर्क का एक गुच्छा मात्र है? क्या सभी उपद्रव केवल समानांतर गणना और अधिक शक्तिशाली मशीनों के कारण होते हैं? अक्सर, जब मैं तथाकथित गहन शिक्षण समाधानों की जांच करता हूं, तो यह ऐसा दिखता है। (तंत्रिका नेटवर्क के लिए कुछ व्यावहारिक, वास्तविक दुनिया के उपयोग क्या हैं? 5 तंत्रिका नेटवर्क उपयोग मामलों में पता लगाएं, जो आपको प्रौद्योगिकी को बेहतर ढंग से समझने में मदद करेंगे।)
जैसा कि मैंने कहा, हालांकि, मैं संदेहवादी क्लब से संबंधित हूं, और मैं आमतौर पर अभी तक समर्थित सबूतों से सावधान नहीं हूं। एक बार के लिए, आइए, हम पूर्वाग्रह से अलग हों, और यदि कोई हो, तो तंत्रिका नेटवर्क के संबंध में गहन सीखने में नई उभरती हुई तकनीकों की गहन जाँच की कोशिश करें।
जब थोड़ा गहरा खुदाई करते हैं, तो हम गहरी शिक्षा के क्षेत्र में कुछ नई इकाइयों, आर्किटेक्चर और तकनीकों को खोजते हैं। इन नवाचारों में से कुछ एक छोटे वजन को ले जाते हैं, जैसे ड्रॉपआउट परत द्वारा शुरू किए गए यादृच्छिककरण। कुछ अन्य, हालांकि, अधिक महत्वपूर्ण परिवर्तनों के लिए जिम्मेदार हैं। और, निश्चित रूप से, उनमें से अधिकांश कम्प्यूटेशनल संसाधनों की बड़ी उपलब्धता पर भरोसा करते हैं क्योंकि वे काफी कम्प्यूटेशनल रूप से महंगे हैं।
मेरी राय में, तंत्रिका नेटवर्क के क्षेत्र में तीन मुख्य नवाचार हुए हैं, जिन्होंने इसकी वर्तमान लोकप्रियता हासिल करने में गहरी शिक्षा में महत्वपूर्ण योगदान दिया है: कन्वेन्शनल न्यूरल नेटवर्क (CNN), लंबी अवधि की मेमोरी (LSTM) इकाइयाँ और जेनरल एडवरसैरियल नेटवर्क (GANs) )।
संवैधानिक तंत्रिका नेटवर्क (CNNs)
गहरी सीखने का बड़ा धमाका - या कम से कम जब मैंने पहली बार उछाल सुना - एक छवि मान्यता परियोजना में हुआ, 2012 में इमेजनेट लार्ज स्केल विजुअल रिकॉग्निशन चैलेंज। स्वचालित रूप से छवियों को पहचानने के लिए, एक सजातीय तंत्रिका नेटवर्क आठ परतों - एलेक्सनेट - का उपयोग किया गया था। पहले पांच परतें परतदार परतें थीं, उनमें से कुछ अधिकतम-पूलिंग परतों के बाद थीं, और अंतिम तीन परतें पूरी तरह से जुड़ी हुई परतें थीं, सभी एक गैर-संतृप्त ReLU सक्रियण फ़ंक्शन के साथ थीं। एलेक्सनेट नेटवर्क ने 15.3% की शीर्ष-पांच त्रुटि हासिल की, रनर अप की तुलना में 10.8 प्रतिशत अधिक अंक। यह एक बड़ी उपलब्धि थी!
नो बग्स, नो स्ट्रेस - योर स्टेप बाय स्टेप गाइड बाय स्टेप गाइड टू लाइफ-चेंजिंग सॉफ्टवेर विदाउट योर लाइफ

जब कोई भी सॉफ़्टवेयर गुणवत्ता की परवाह नहीं करता है तो आप अपने प्रोग्रामिंग कौशल में सुधार कर सकते हैं।
मल्टीलेयर आर्किटेक्चर के अलावा, एलेक्सनेट का सबसे बड़ा नवाचार था कंफ्यूजेशनल लेयर।
एक दृढ़ नेटवर्क में पहली परत हमेशा एक दृढ़ परत होती है। एक दृढ़ परत में प्रत्येक न्यूरॉन इनपुट छवि के एक विशिष्ट क्षेत्र (ग्रहणशील क्षेत्र) पर केंद्रित होता है और इसके भारित कनेक्शन के माध्यम से ग्रहणशील क्षेत्र के लिए एक फिल्टर के रूप में कार्य करता है। फिल्टर को स्लाइड करने के बाद, न्यूरॉन के बाद न्यूरॉन, सभी छवि ग्रहणशील क्षेत्रों पर, आक्षेपिक परत का आउटपुट एक सक्रियण मानचित्र या सुविधा मानचित्र का उत्पादन करता है, जिसे एक फीचर पहचानकर्ता के रूप में इस्तेमाल किया जा सकता है।
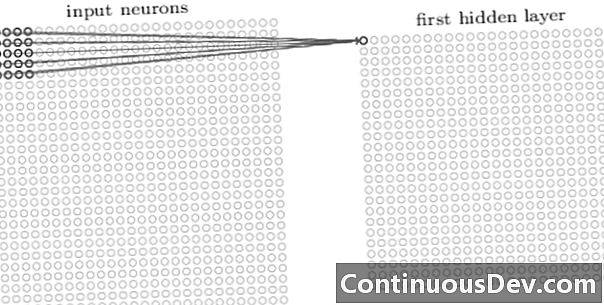
एक दूसरे के ऊपर और अधिक दृढ़ परतें जोड़कर, सक्रियण मानचित्र इनपुट छवि से अधिक से अधिक जटिल विशेषताओं का प्रतिनिधित्व कर सकता है। इसके अलावा, अक्सर एक सजा हुआ तंत्रिका नेटवर्क वास्तुकला में, मैपिंग फ़ंक्शन की अशुद्धता को बढ़ाने के लिए, नेटवर्क की मजबूती में सुधार करने और ओवरफिटिंग को नियंत्रित करने के लिए इन सभी दोषपूर्ण परतों के बीच कुछ और परतें होती हैं।
अब जब हम इनपुट छवि से उच्च-स्तरीय विशेषताओं का पता लगा सकते हैं, तो हम पारंपरिक वर्गीकरण के लिए नेटवर्क के अंत में एक या एक से अधिक पूरी तरह से जुड़ी हुई परतें जोड़ सकते हैं। नेटवर्क का यह अंतिम भाग इनपुट के रूप में संकेंद्रित परतों के आउटपुट को लेता है और एन-आयामी वेक्टर को आउटपुट करता है, जहां एन कक्षाओं की संख्या है। इस एन-आयामी वेक्टर में प्रत्येक संख्या एक वर्ग की संभावना का प्रतिनिधित्व करती है।
दिन में, मैंने अक्सर तंत्रिका नेटवर्क पर उनकी वास्तुकला की पारदर्शिता की कमी और परिणामों की व्याख्या और व्याख्या करने की असंभवता के बारे में सुना। यह आपत्ति आजकल गहन शिक्षण नेटवर्क के संबंध में कम और अधिक बार आ रही है। ऐसा लगता है कि अब यह वर्गीकरण में उच्च सटीकता के लिए ब्लैक-बॉक्स प्रभाव का व्यापार करने के लिए स्वीकार्य है।
लॉन्ग शॉर्ट-टर्म मेमोरी (LSTM) इकाइयाँ
गहरे सीखने वाले तंत्रिका नेटवर्क द्वारा उत्पादित एक और बड़ा सुधार समय श्रृंखला विश्लेषण में आवर्तक तंत्रिका नेटवर्क (आरएनएन) के माध्यम से देखा गया है।
आवर्तक तंत्रिका नेटवर्क एक नई अवधारणा नहीं है। वे पहले से ही 90 के दशक में उपयोग किए गए थे और समय (बीपीटीटी) एल्गोरिथ्म के माध्यम से बैकप्रोपेगेशन के साथ प्रशिक्षित थे। 90 के दशक में, हालांकि, कम्प्यूटेशनल संसाधनों की मात्रा को देखते हुए उन्हें प्रशिक्षित करना अक्सर असंभव था। हालांकि, आजकल उपलब्ध कम्प्यूटेशनल शक्ति में वृद्धि के कारण, न केवल आरएनएन को प्रशिक्षित करना संभव हो गया है, बल्कि उनकी वास्तुकला की जटिलता को भी बढ़ाना संभव हो गया है। यही बात है न? खैर, बिल्कुल नहीं।
1997 में, एक समय श्रृंखला में संबंधित अतीत के संस्मरण से बेहतर तरीके से निपटने के लिए एक विशेष तंत्रिका इकाई की शुरुआत की गई: LSTM इकाई। आंतरिक फाटकों के संयोजन के माध्यम से, एक LSTM इकाई प्रासंगिक पिछली जानकारी को याद रखने या एक समय श्रृंखला में अप्रासंगिक अतीत की सामग्री को भूलने में सक्षम है। LSTM नेटवर्क एक विशेष प्रकार का आवर्तक तंत्रिका नेटवर्क है, जिसमें LSTM इकाइयाँ शामिल हैं। LSTM- आधारित RNN का अनकहा गया संस्करण चित्र 2 में दिखाया गया है।
सीमित लंबी मेमोरी क्षमता की समस्या को दूर करने के लिए, LSTM इकाइयां एक अतिरिक्त छिपे हुए राज्य - सेल राज्य का उपयोग करती हैं सी (टी) - मूल छिपे हुए राज्य से प्राप्त ज (टी)। सी (टी) नेटवर्क मेमोरी का प्रतिनिधित्व करता है। एक विशेष संरचना, जिसे गेट कहा जाता है, आपको सेल स्थिति को हटाने (भूल जाने) या जोड़ने (याद रखने) की अनुमति देता है सी (टी) इनपुट मानों के आधार पर हर बार चरण एक्स (टी) और पिछली छिपी हुई अवस्था ज (टी -1)। प्रत्येक गेट 0 और 1 के बीच आउटपुट मानों को जोड़ने या हटाने के लिए कौन सी जानकारी तय करता है। सेल राज्य द्वारा गेट आउटपुट पॉइंटवाइज़ को गुणा करके सी (टी -1), जानकारी हटा दी जाती है (गेट का आउटपुट = 0) या रखा जाता है (गेट का आउटपुट = १)।
चित्र 2 में, हम एक LSTM इकाई की नेटवर्क संरचना देखते हैं। प्रत्येक LSTM इकाई में तीन द्वार होते हैं। शुरुआत में "गेट गेट लेयर" पिछली सेल स्थिति से जानकारी को फ़िल्टर करता है सी (टी -1) वर्तमान इनपुट के आधार पर एक्स (टी) और पिछले सेल की छिपी अवस्था ज (टी -1)। इसके बाद, एक "इनपुट गेट लेयर" और एक "टैन्ह लेयर" के संयोजन से तय होता है कि कौन सी जानकारी को पहले से, पहले से फ़िल्टर्ड, सेल स्टेट में जोड़ना है सी (टी -1)। अंत में, अंतिम गेट, "आउटपुट गेट," यह तय करता है कि अद्यतन सेल स्थिति से कौन सी जानकारी है सी (टी) अगले छिपे हुए राज्य में समाप्त होता है ज (टी).
LSTM इकाइयों के बारे में अधिक जानकारी के लिए, क्रिस्टोफर ओलाह द्वारा GitHub ब्लॉग पोस्ट "अंडरस्टैंडिंग LSTM नेटवर्क" की जाँच करें।
चित्रा 2. एक एलएसटीएम सेल की संरचना (इयान गुडफेलो, योशुआ बेंगियो और आरोन कोर्टविल द्वारा "डीप लर्निंग" से पुन: प्रस्तुत)। LSTM इकाइयों के भीतर तीन फाटकों पर ध्यान दें। बाएं से दाएं: भूल जाओ गेट, इनपुट गेट और आउटपुट गेट।
LSTM इकाइयों का उपयोग कई बार श्रृंखला की भविष्यवाणी समस्याओं में सफलतापूर्वक किया गया है, लेकिन विशेष रूप से भाषण मान्यता, प्राकृतिक भाषा प्रसंस्करण (एनएलपी) और मुक्त पीढ़ी में।
जनरेशनल एडवरसियरी नेटवर्क (GAN)

एक जेनरेटिव एडवरसैरियल नेटवर्क (GAN) दो डीप लर्निंग नेटवर्क, जनरेटर और डिस्क्रिमिनेटर से बना है।
एक जनरेटर जी एक परिवर्तन है जो इनपुट शोर को बदल देता है z एक टेंसर में - आमतौर पर एक छवि - एक्स (एक्स= जी (z))। DCGAN जनरेटर नेटवर्क के लिए सबसे लोकप्रिय डिजाइनों में से एक है। CycleGAN नेटवर्क में, जनरेटर अपलिंप करने के लिए कई ट्रांसपोज़्ड कनफ़ॉर्मेशन करता है z अंततः छवि उत्पन्न करने के लिए एक्स (चित्र तीन)।
उत्पन्न छवि एक्स फिर डिस्क्रिमिनेटर नेटवर्क में खिलाया जाता है। डिस्क्रिमिनेटर नेटवर्क प्रशिक्षण सेट में वास्तविक छवियों और जनरेटर नेटवर्क द्वारा उत्पन्न छवि की जांच करता है और एक आउटपुट तैयार करता है डी (एक्स), जो उस छवि की संभावना है एक्स सत्य है।
जनरेटर और डिस्क्रिमिनेटर दोनों को उत्पादन करने के लिए बैकप्रोपैगैस एल्गोरिथ्म का उपयोग करके प्रशिक्षित किया जाता है डी (एक्स)=1 उत्पन्न छवियों के लिए। दोनों नेटवर्क को खुद को बेहतर बनाने के लिए प्रतिस्पर्धा करने वाले चरणों में प्रशिक्षित किया जाता है। GAN मॉडल अंततः उन छवियों को परिवर्तित और निर्मित करता है जो वास्तविक दिखती हैं।

GANs को एनीमे, मानव आकृतियाँ और यहां तक कि वैन गॉघ जैसी उत्कृष्ट कृतियों को बनाने के लिए छवि टेंसरों पर सफलतापूर्वक लागू किया गया है। (तंत्रिका नेटवर्क के अन्य आधुनिक उपयोगों के लिए, 6 बड़े अग्रिमों को आप कृत्रिम तंत्रिका नेटवर्क में शामिल कर सकते हैं।)
निष्कर्ष
तो, क्या स्टेरॉयड पर तंत्रिका नेटवर्क का सिर्फ एक गुच्छा सीखना बहुत आसान है? आंशिक रूप से।
हालांकि यह निर्विवाद है कि तेजी से हार्डवेयर प्रदर्शनों ने अधिक जटिल, बहु-परत और यहां तक कि आवर्तक तंत्रिका आर्किटेक्चर के सफल प्रशिक्षण में बड़े पैमाने पर योगदान दिया है, यह भी सच है कि किस क्षेत्र में कई नए नवीन तंत्रिका इकाइयों और आर्किटेक्चर का प्रस्ताव किया गया है अब गहरी सीख कहा जाता है।
विशेष रूप से, हमने CNNs, LSTM इकाइयों और GAN में छवि परतों, छवि प्रसंस्करण, समय श्रृंखला विश्लेषण और मुक्त पीढ़ी के क्षेत्र में सबसे सार्थक नवाचारों में से कुछ की पहचान की है।
इस बिंदु पर करने के लिए केवल एक चीज बची हुई है और यह जानने के लिए कि हमारे अपने डेटा समस्याओं के लिए नए मजबूत समाधानों के साथ गहरे शिक्षण नेटवर्क हमारी कितनी मदद कर सकते हैं।