
विषय

स्रोत: Kran77 / Dreamstime.com
ले जाओ:
डीप लर्निंग मॉडल कंप्यूटर को अपने दम पर सोचने के लिए सिखा रहे हैं, कुछ बहुत ही मजेदार और दिलचस्प परिणाम के साथ।
डीप लर्निंग को अधिक से अधिक डोमेन और उद्योगों पर लागू किया जा रहा है। चालक रहित कारों से, गो खेलने के लिए, छवियां संगीत उत्पन्न करने के लिए, हर दिन नए गहरे शिक्षण मॉडल सामने आ रहे हैं। यहाँ हम कई लोकप्रिय गहरे सीखने के मॉडल पर चलते हैं। वैज्ञानिक और डेवलपर इन मॉडलों को ले रहे हैं और उन्हें नए और रचनात्मक तरीकों से संशोधित कर रहे हैं। हमें उम्मीद है कि यह प्रदर्शन आपको यह देखने के लिए प्रेरित कर सकता है कि क्या संभव है। (कृत्रिम बुद्धिमत्ता में प्रगति के बारे में जानने के लिए, क्या विल कंप्यूटर मानव मस्तिष्क का अनुकरण करने में सक्षम हैं?)
तंत्रिका शैली
जब कोई भी सॉफ़्टवेयर गुणवत्ता की परवाह नहीं करता है तो आप अपने प्रोग्रामिंग कौशल में सुधार कर सकते हैं।
तंत्रिका कथाकार

न्यूरल स्टोरीटेलर एक मॉडल है जो एक छवि को दिए जाने पर, छवि के बारे में एक रोमांस कहानी उत्पन्न कर सकता है। इसका एक मजेदार खिलौना है और फिर भी आप भविष्य की कल्पना कर सकते हैं और उस दिशा को देख सकते हैं जिसमें ये सभी कृत्रिम बुद्धिमत्ता मॉडल चल रहे हैं।

उपरोक्त फ़ंक्शन "स्टाइल-शिफ्टिंग" ऑपरेशन है जो मॉडल को उपन्यास से कहानियों की शैली में मानक छवि कैप्शन को स्थानांतरित करने की अनुमति देता है। स्टाइल शिफ्टिंग "A Neural Algorithm of Artistic Style" से प्रेरित था।
डेटा
डेटा के दो मुख्य स्रोत हैं जो इस मॉडल में उपयोग किए जाते हैं। MSCOCO Microsoft का एक डेटासेट है जिसमें लगभग 300,000 चित्र हैं, जिनमें प्रत्येक चित्र में पाँच कैप्शन हैं। MSCOCO केवल पर्यवेक्षित डेटा का उपयोग किया जा रहा है, जिसका अर्थ है कि यह एकमात्र डेटा है जहाँ मनुष्यों को जाना था और प्रत्येक छवि के लिए स्पष्ट रूप से कैप्शन लिखना था।
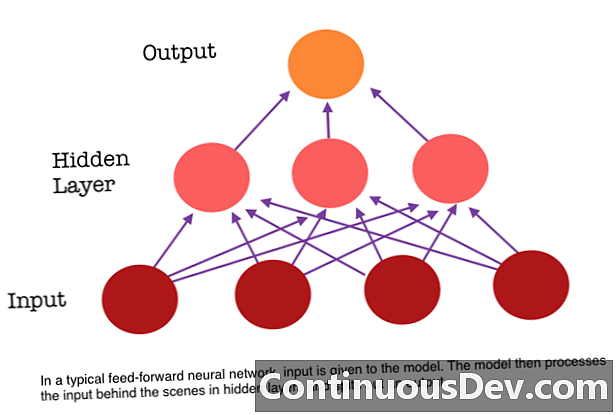
फ़ीड-फ़ॉरवर्ड न्यूरल नेटवर्क की एक प्रमुख सीमा यह है कि इसमें कोई मेमोरी नहीं है। प्रत्येक भविष्यवाणी पिछली गणनाओं से स्वतंत्र है, जैसे कि यह पहली और एकमात्र भविष्यवाणी थी जो कभी नेटवर्क बनाई गई थी। लेकिन कई कार्यों के लिए, जैसे कि एक वाक्य या पैराग्राफ का अनुवाद करना, इनपुट में अनुक्रमिक और शंक्वाकार रूप से संबंधित डेटा शामिल होना चाहिए। उदाहरण के लिए, आस-पास के शब्दों द्वारा प्रदान किए गए कोन के बिना एक वाक्य में एक शब्द का अर्थ बनाना मुश्किल होगा।
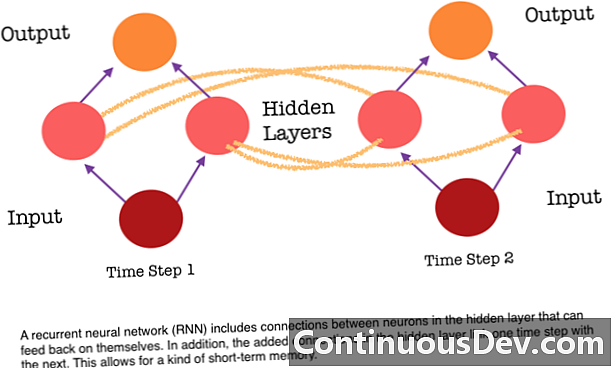
आरएनएन अलग-अलग हैं क्योंकि वे न्यूरॉन्स के बीच कनेक्शन का एक और सेट जोड़ते हैं। ये लिंक एक गुप्त परत में न्यूरॉन्स से सक्रियण को अनुक्रम में अगले चरण में खुद को वापस खिलाने की अनुमति देते हैं। दूसरे शब्दों में, हर कदम पर, एक छिपी हुई परत उसके नीचे की परत से और अनुक्रम में पिछले चरण से दोनों सक्रियण प्राप्त करती है। यह संरचना अनिवार्य रूप से आवर्तक तंत्रिका नेटवर्क मेमोरी देती है। तो वस्तु का पता लगाने के कार्य के लिए, एक RNN कुत्तों की अपनी पिछली वर्गीकरण को आकर्षित करने में मदद कर सकता है ताकि यह निर्धारित किया जा सके कि वर्तमान छवि एक कुत्ता है।
चार-आरएनएन टेड
छिपी हुई परत में यह लचीली संरचना आरएनएन को चरित्र-स्तरीय भाषा के मॉडल के लिए बहुत अच्छा बनाती है। चार आरएनएन, मूल रूप से लेडी करपैथी द्वारा बनाया गया, एक मॉडल है जो इनपुट के रूप में एक फाइल लेता है और एक अनुक्रम में अगले चरित्र की भविष्यवाणी करने के लिए सीखने के लिए आरएनएन को प्रशिक्षित करता है। आरएनएन चरित्र द्वारा चरित्र उत्पन्न कर सकता है जो मूल प्रशिक्षण डेटा की तरह दिखेगा। एक डेमो को विभिन्न टेड टॉक्स के टेप का उपयोग करके प्रशिक्षित किया गया है। मॉडल को एक या कई कीवर्ड फ़ीड करें और यह टेड टॉक की आवाज / शैली में कीवर्ड (ओं) के बारे में एक पैठ उत्पन्न करेगा।
निष्कर्ष
ये मॉडल मशीन इंटेलिजेंस में नई सफलता दिखाते हैं जो गहरी शिक्षा के कारण संभव हो गए हैं। गहन शिक्षा से पता चलता है कि हम उन समस्याओं को हल कर सकते हैं जिन्हें हम पहले कभी नहीं सुलझा सकते थे, और हम अभी तक उस पठार तक नहीं पहुंचे हैं। गहन सीखने वाले नवाचार के परिणामस्वरूप अगले कुछ वर्षों में ड्राइवर रहित कारों की तरह कई और रोमांचक चीजें देखने की उम्मीद है।