विषय
- कम समय में डेटा की एक विशाल मात्रा को संभालना
- सार्थक आउटपुट प्राप्त करने के लिए डेटा की सफाई और स्वरूपण
- नो बग्स, नो स्ट्रेस - योर स्टेप बाय स्टेप गाइड बाय स्टेप गाइड टू लाइफ-चेंजिंग सॉफ्टवेर विदाउट योर लाइफ
- डेटा का दृश्य प्रतिनिधित्व
- आवेदन स्केलेबल होना चाहिए
- डेटा विश्लेषण के लिए उपयुक्त उपकरण या प्रौद्योगिकी का चयन
- निष्कर्ष
स्रोत: निल्स एकरमैन / ड्रीमस्टाइम डॉट कॉम
ले जाओ:
बड़ा डेटा व्यवसायों के लिए एक अमूल्य संसाधन हो सकता है, लेकिन कई न तो उन चुनौतियों पर विचार करते हैं जो इसे लागू करने और विश्लेषण करने में शामिल हैं।
हालांकि डेटा संग्रह और विश्लेषण दशकों से आसपास रहे हैं, हाल के वर्षों में बड़े डेटा एनालिटिक्स ने तूफान से व्यापार की दुनिया को ले लिया है। हालाँकि, यह कुछ सीमाओं के साथ आता है। इस लेख में, हम निकट भविष्य में बड़ी डेटा एनालिटिक्स कंपनियों की चुनौतियों के बारे में बात करेंगे।
जैसा कि नाम से पता चलता है, बड़ा डेटा वॉल्यूम और व्यावसायिक जटिलता के संदर्भ में बहुत बड़ा है। यह विभिन्न स्वरूपों में आता है, जैसे कि संरचित डेटा, अर्ध-संरचित डेटा और असंरचित डेटा और डेटा स्रोतों की एक विस्तृत सरणी से। बिग डेटा एनालिटिक्स त्वरित, कार्रवाई योग्य अंतर्दृष्टि के लिए उपयोगी है। चूंकि बड़ा डेटा विश्लेषण विभिन्न मापदंडों और आयामों पर आधारित है, यह कुछ चुनौतियों के साथ आता है, जिनमें शामिल हैं:
- सीमित समय में बड़ी मात्रा में डेटा को संभालना
- वांछित सार्थक आउटपुट प्राप्त करने के लिए डेटा को साफ करना और उसे प्रारूपित करना
- दृश्य प्रारूप में डेटा का प्रतिनिधित्व करना
- एप्लिकेशन को स्केलेबल बनाना
- विश्लेषण के लिए उचित तकनीक / उपकरण का चयन करना
कम समय में डेटा की एक विशाल मात्रा को संभालना
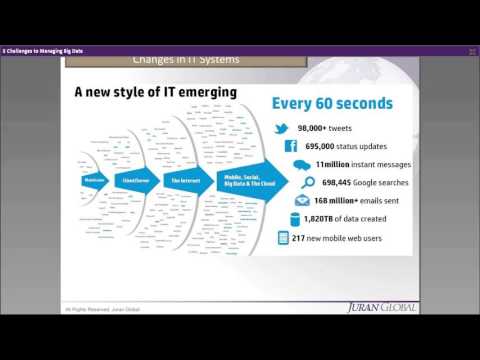
सीमित समय में बड़ी मात्रा में डेटा को संभालना एक महत्वपूर्ण चुनौती है, इस तथ्य को देखते हुए कि रोजाना 2.5 क्विंटल से अधिक डेटा का निर्माण होता है। शीर्ष पर, हम उन सभी स्रोतों का नाम भी नहीं दे सकते हैं, जिनसे डेटा बनाया जा रहा है - डेटा स्रोत सेंसर, सोशल मीडिया, लेन-देन-आधारित डेटा, सेलुलर डेटा या किसी अन्य स्रोत के असंख्य हो सकते हैं।
महत्वपूर्ण व्यावसायिक निर्णयों को प्रभावी ढंग से करने के लिए, हमारे पास एक मजबूत आईटी अवसंरचना होनी चाहिए जो कि डेटा को तेजी से पढ़ने और वास्तविक समय की पहुंच प्रदान करने में सक्षम होना चाहिए। इसलिए, हम देखते हैं कि चुनौती यह है कि लागत और समय-प्रभावी तरीके से भारी मात्रा में डेटा की अंतर्दृष्टि कैसे निकाली जाए।
अगर हम जटिल डेटा को संभालने के बारे में बात करते हैं, तो पहला बड़ा डेटा टूल जो दिमाग में आता है वह है अपाचे हडोप। Hadoop में हमारे पास MapReduce है, जो एप्लिकेशन को छोटे टुकड़ों में विभाजित करने की क्षमता रखता है। हर एक टुकड़े को एक क्लस्टर के अंदर एक नोड पर निष्पादित किया जाता है। Hadoop में कई उपयोगी सुविधाएँ हैं और व्यापक रूप से इसका उपयोग किया जाता है, लेकिन हम इस तथ्य को अनदेखा नहीं कर सकते हैं कि संगठनों को एक ठोस समाधान की आवश्यकता है जो न्यूनतम डाउनटाइम की अनुमति देते समय संरचित और असंरचित दोनों डेटा की एक सरणी को संभालने में सक्षम होना चाहिए। इन सबसे ऊपर, Hadoop में कुछ अतिरिक्त चुनौतियाँ हैं, जिनमें शामिल हैं:
- डेटा प्रबंधन से संबंधित चुनौतियां
- नौकरी के समय निर्धारण से संबंधित चुनौतियां
- संसाधन साझाकरण से संबंधित चुनौतियाँ
- क्लस्टर प्रबंधन से संबंधित चुनौतियां
IBM InfoSphere BigInsights, जो Hadoop के शीर्ष पर बनाया गया है, इन महत्वपूर्ण व्यावसायिक आवश्यकताओं को पूरा करने की क्षमता रखता है। साथ ही यह अनुकूलता बनाए रखने की क्षमता भी रखता है।
सार्थक आउटपुट प्राप्त करने के लिए डेटा की सफाई और स्वरूपण
डेटा सफाई डेटा विश्लेषण का एक अभिन्न हिस्सा है। वास्तव में, इस पर कोई सांख्यिकीय विश्लेषण करने की तुलना में डेटा को साफ करना अधिक समय लेने वाला कार्य है। सांख्यिकीय डेटा विश्लेषण करते समय, डेटा को निम्नलिखित पाँच चरणों से गुजरना पड़ता है:
नो बग्स, नो स्ट्रेस - योर स्टेप बाय स्टेप गाइड बाय स्टेप गाइड टू लाइफ-चेंजिंग सॉफ्टवेर विदाउट योर लाइफ

जब कोई भी सॉफ़्टवेयर गुणवत्ता की परवाह नहीं करता है तो आप अपने प्रोग्रामिंग कौशल में सुधार कर सकते हैं।
चित्र 1: डेटा की सफाई और विश्लेषण के चरण
उपरोक्त आंकड़े में हम डेटा विश्लेषण चरणों का अवलोकन देख सकते हैं। प्रत्येक बॉक्स एक चरण का प्रतिनिधित्व करता है जिसके माध्यम से डेटा गुजरता है। पहले तीन चरण डेटा-सफाई तंत्र के अंतर्गत आते हैं, जबकि अंतिम दो डेटा विश्लेषण का हिस्सा हैं।
- कच्चा डेटा - यह डेटा है जैसे ही यह आता है। इस स्थिति में तीन संभावित समस्याएं हो सकती हैं:
- डेटा में उपयुक्त हेडर नहीं हो सकता है।
- डेटा में गलत डेटा प्रकार हो सकते हैं।
- डेटा में अज्ञात या अवांछित वर्ण एन्कोडिंग हो सकती है।
- तकनीकी रूप से सही डेटा - एक बार जब कच्चे डेटा को उपरोक्त सूचीबद्ध विसंगतियों से छुटकारा पाने के लिए संशोधित किया जाता है, तो इसे "तकनीकी रूप से सही डेटा" कहा जाता है।
- लगातार डेटा - इस चरण में, डेटा किसी भी तरह के सांख्यिकीय विश्लेषण के संपर्क में आने के लिए तैयार है, और विश्लेषण के लिए शुरुआती बिंदु के रूप में इस्तेमाल किया जा सकता है।
- सांख्यिकीय परिणाम और आउटपुट - सांख्यिकीय परिणाम प्राप्त करने के बाद, उन्हें पुन: उपयोग के लिए संग्रहीत किया जा सकता है। इन परिणामों को प्रारूपित भी किया जा सकता है ताकि उनका उपयोग विभिन्न प्रकार की रिपोर्टों को प्रकाशित करने के लिए किया जा सके।
डेटा का दृश्य प्रतिनिधित्व
एक अच्छी तरह से संरचित प्रारूप में डेटा का प्रतिनिधित्व करना, जो दर्शकों के लिए पठनीय और समझने योग्य है, महत्वपूर्ण है। असंरचित डेटा को संभालना और फिर इसे एक दृश्य प्रारूप में प्रस्तुत करना एक चुनौतीपूर्ण काम हो सकता है जो निकट भविष्य में बड़े डेटा को लागू करने वाले संगठनों का सामना करने जा रहे हैं। इस ज़रूरत को पूरा करने के लिए, डेटा को दर्शाने के लिए विभिन्न प्रकार के ग्राफ़ या तालिकाओं का उपयोग किया जा सकता है।
आवेदन स्केलेबल होना चाहिए
दिन-ब-दिन डेटा की बढ़ती मात्रा को देखते हुए, सबसे बड़ी चुनौती संगठनों का सामना करना पड़ रहा है जो स्केलेबिलिटी फैक्टर है। स्केलेबल एप्लिकेशन रखने के लिए, हम डेटा एकत्रित करते समय निम्नलिखित चुनौतियों का सामना करते हैं:
- डेटा सेवाओं को कई तकनीकी ढेर पर तैनात किया जाता है:
- सामने के छोर के लिए अपाचे / पीएचपी
- डेटाबेस या सामने के छोर के साथ बातचीत करने के लिए प्रोग्रामिंग भाषाओं (जैसे जावा या स्काला) का उपयोग
चूंकि डेटाबेस और फ्रंट एंड के बीच कई लेयर्स (अलग-अलग टेक्नोलॉजी स्टैक्स से युक्त) होती हैं, इसलिए डेटा का ट्रैवर्सल में समय लगता है। इसलिए जब एप्लिकेशन स्केल करने की कोशिश करता है, तो प्रदर्शन कम हो जाता है। एक समाधान के रूप में, वास्तुकला और प्रौद्योगिकी स्टैक को प्रदर्शन के मुद्दों से बचने और स्केलेबिलिटी बढ़ाने के लिए ठीक से डिज़ाइन किया जाना चाहिए।
उत्पादन डेटा सेवाओं में न्यूनतम विलंबता होनी चाहिए। जब कोई आवेदन बढ़ता है, तो प्रत्येक अनुरोध का जवाब समय प्रमुख मुद्दों में से एक है। जैसे-जैसे डेटा की मात्रा बढ़ती है, डेटा सर्विस क्षेत्र में सर्वोत्तम प्रथाओं को लागू करके विलंबता समस्या को ठीक से नियंत्रित किया जाता है।
डेटा विश्लेषण के लिए उपयुक्त उपकरण या प्रौद्योगिकी का चयन
भले ही हम डेटा को इकट्ठा करने और संग्रहीत करने के लिए दृष्टिकोण करते हैं, अगर हमारे पास विश्लेषण के लिए एक उपयुक्त उपकरण नहीं है, तो इन चीजों को जगह में रखने का कोई फायदा नहीं है। डेटा विश्लेषण के लिए उपकरणों का चयन करते समय हमें अतिरिक्त देखभाल करने की आवश्यकता है। एक बार जब हम उपकरण को अंतिम रूप दे देते हैं, तो हम आसानी से दूसरे पर स्विच नहीं कर सकते। इसलिए, विश्लेषण के लिए उपकरणों का चयन करते समय, हमें निम्नलिखित पर विचार करना चाहिए:
- डेटा की मात्रा
- लेन-देन की मात्रा
- विरासत डेटा प्रबंधन और अनुप्रयोग
निष्कर्ष
यहां बताई गई चुनौतियों का अंदाजा आसानी से लगाया जा सकता है, लेकिन कौन जानता है कि दूसरी, अप्रत्याशित चुनौतियां आगे बढ़ सकती हैं? बड़े डेटा के साथ काम करते समय, चुनौतियों का पूर्वानुमान लगाने और किसी भी मुद्दे के लिए योजना बनाने की कोशिश करने का यह एक अच्छा विचार है।